CoCa Models
Summary of CoCa model based on the preprint by Yu, Wang, et. al.
CoCa stands for Contrastive Captioner, a type of computer vision model. According to the creators of CoCa at Google Research by Yu, Wang, et. al, such models are capable of being Image-Text Foundation Models like BERT, T5, GPT-\(n\), ... meaning it demonstrates generic multi-tasking capabilities through zero-shot, few-shot, or transfer learning. This blog posts serves to summarize their preprint in an approachable way.
Motivation
Existing foundation models are typically trained on data on the scale of what is contained across the internet, and are thereby great for appropriating, repurposing, and transferring to other tasks without high training costs. A general thread of investigations performed with foundation models involves cross-modal alignment tasks, or the aligning and understanding of information across different modalities or types of data (think images, text, audio, or video). In particular, we will see that the main tasks at hand involve both vision and language.
In particular, there are multiple pre-CoCa "paradigms" or candidate architectures for vision and vision-language tasks which could qualify as foundation models:
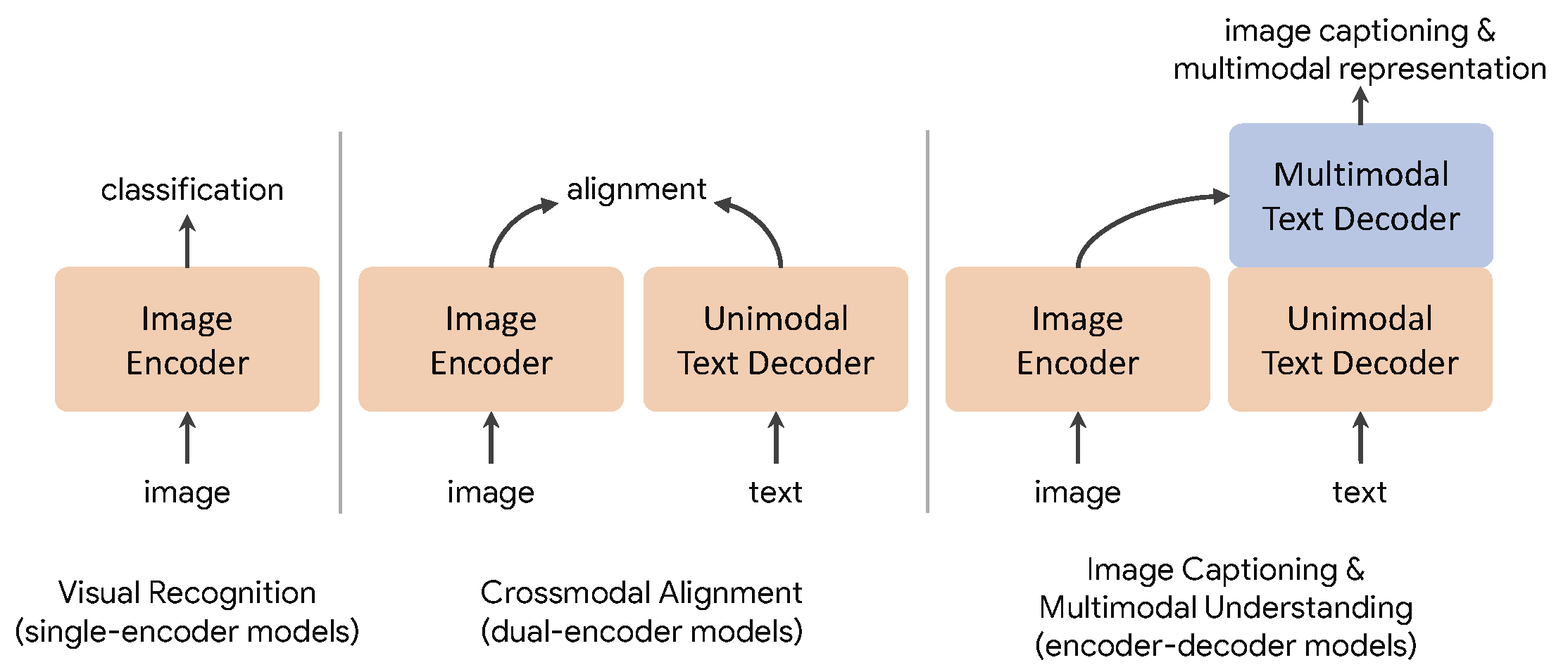
Single-Encoder
A single encoder is an image encoder trained with cross-entropy loss on large image classification datasets like ImageNet.
- Think: "a CNN encodes the input image into a compact, fixed-length vector."
- Used for: image encoding for classification, retrieval, etc.
- Caveats: heavy reliance on the provided annotations, having no capacity for natural language, meaning worse for downstream tasks.
Dual-Encoder
A dual encoder contains two encoders jointly optimized by training with contrastive loss (see below) on web-scale, "noisy" (i.e., not cleaned by hand), image-text pairs. Doesn't require human-annotated labels nor data cleaning.
- Think: "two independent encoders each encode one of two input images," a common task in siamese networks where both encoders share weights to improve learning efficiency.
- Used for: image similarity, matching, etc.
- Caveats: despite having the capability to encode textual embeddings along with visual embeddings, they can't perform tasks that involve joint visual and lingual understanding, such as visual question answering.
Encoder-Decoder
An encoder-decoder decodes a text/image pair with Language Modeling (LM) loss.
- Think: "a CNN encodes an image as with single-encoders, but a DCNN will translate any encoding into an image format matching the intended target domain."
- Used for: semantic segmentation, synthesis, image-to-image translation, etc.
- Caveats: while decoded outputs can serve as joint representations for multimodal understanding tasks, these models can't produce text-only representations that correspond to images; hence, not feasible for all cross-modal alignment tasks.
Unification
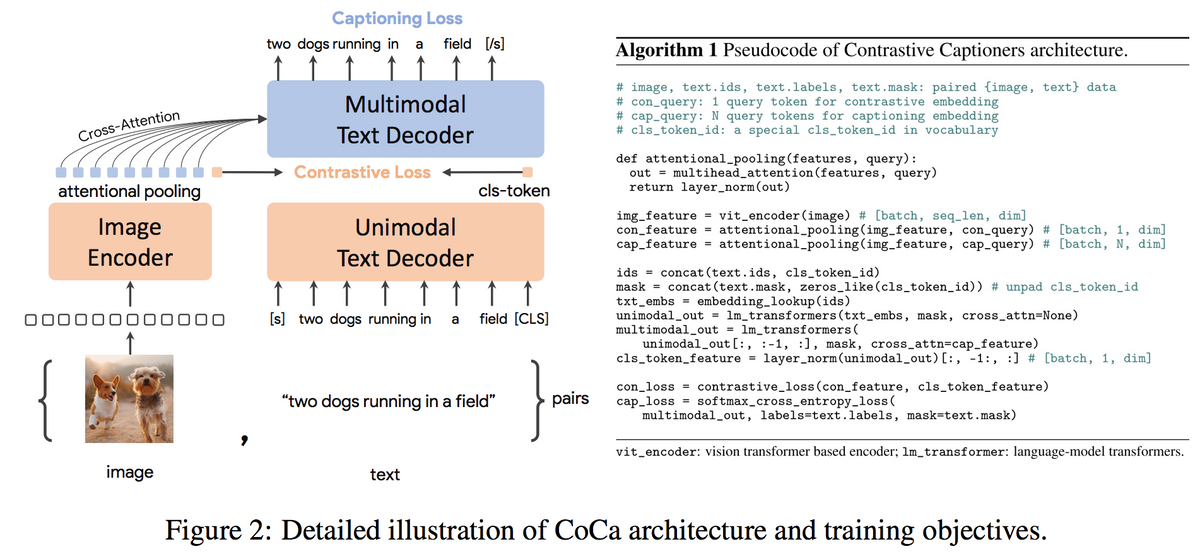
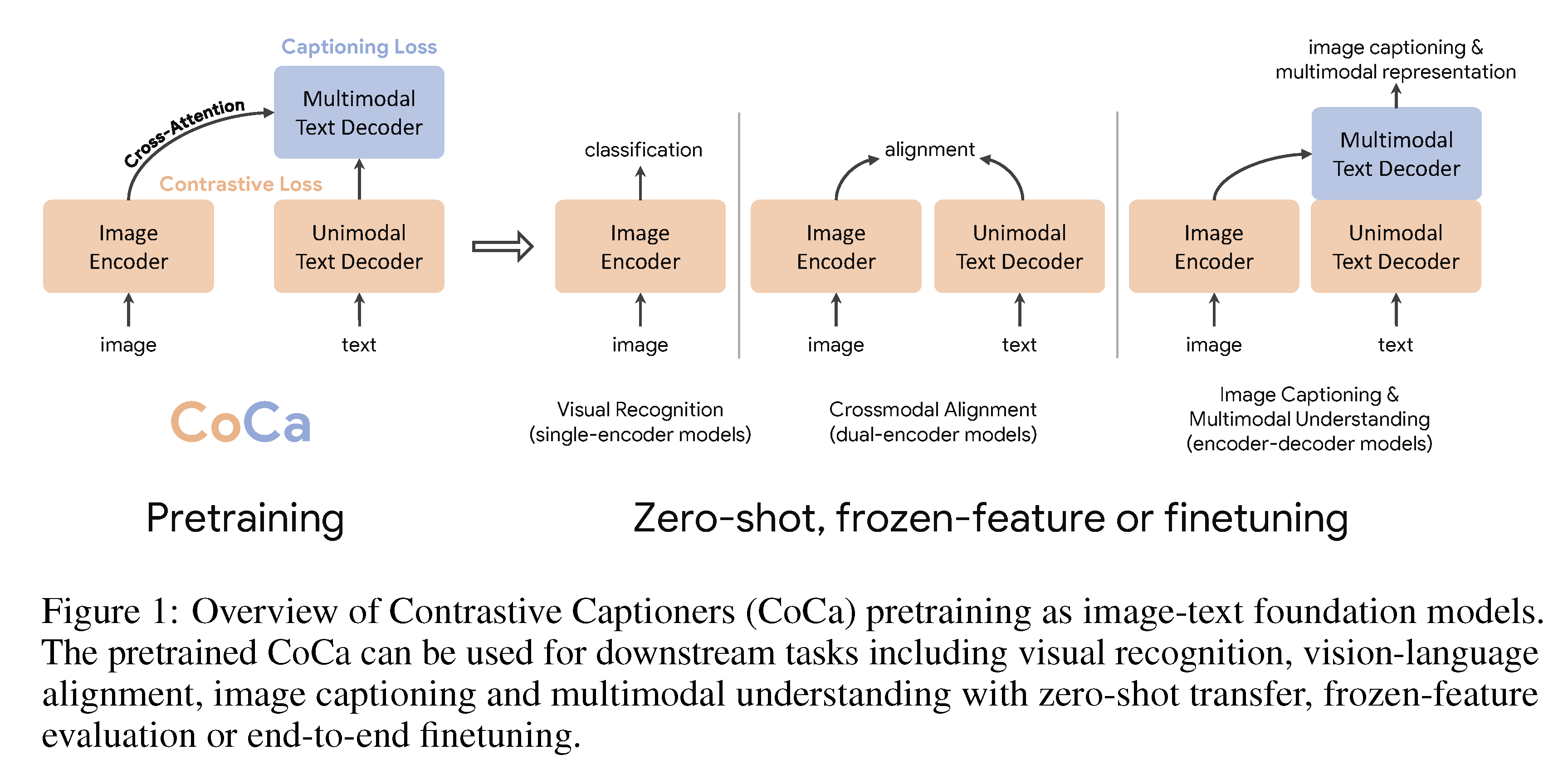
With these three paradigms in mind, the creators of CoCa wished to unify single-encoder, double-encoder, and encoder-decoder architectures, producing a type of image-text foundation model subsuming the capabilities of the rest. In particular, CoCa is a "model family... with a modified encoder-decoder architecture trained with both contrastive loss and captioning (generative) loss."
Losses
Contrastive Loss is a function run over pairs of samples: if a model is able to assign a binary value to any pair describing whether the model deems the pair of inputs to be similar or dissimilar, we punish projecting dissimilar points to similar projections, as well as projecting similar points to dissimilar projections. An example of a model using a contrastive approach is CLIP.
Captioning Loss is a type of generative loss where the accuracy of a generated caption for an image is punished based on how distinct it is deemed from the truth. The score typically used to measure differences between captions is called Cross-Entropy Loss and involves essentially calculating how unlikely it would have been for the true caption to have been output by the model on this input.
Architecture
Cross-attention refers to the mechanism used to establish relationships between information from different modalities: information obtained by encoding one source produces attention weights by which we adjust the importance of various features from more inputs of some other modality. You'll see in the paper's Figure 1 (included below) how text is treated in both a unimodal and multimodal way:
- First text is passed through a unimodal text decoder, and text passes onto the multimodal text decoder;
- Meanwhile, multimodal decoder layers meant to cross-attend to the image encoder outputs are cascaded to the same multimodal text decoder.
The attention mechanisms featured in CoCa are good for capturing global traits as well as region-level features. This is because the multimodal decoder receives a combination of the single embedding of the image in the contrastive objective (good for visual recognition), as well as attends to a sequence of image output tokens to build the caption (good for multimodal understanding). This variability in attention is known as task-specific attentional pooling. A pooler, as written in the paper, is a "single, multi-head attention layer with some learnable queries, with the encoder output as both keys and values." This pooling specifically helps to handle embeddings with different lengths for the two training objectives and naturally adapts the model to whatever task is at hand.
Training
For training,
- Both image annotation data and noisy image-text data are used.
- The contrastive loss function is evaluated between the outputs of the image encoder and the unimodal text decoder.
- The captioning loss function is evaluated for the output of the multimodal decoder.
The captioning objective run on text annotating images is akin to running a single-encoder cross-entropy loss approach. We see elements of all three paradigms present here. In particular, contrastive learning helps to learn global representations, whereas captioning helps most for more fine-grained, region-level features.
Akin to the typical encoder-decoder models, CoCa encodes images to their representations using neural network encoders like Vision Transformer (ViT) or ConvNets, and unimodally decodes texts with a causal masking transformer decoder (i.e., it remains blind to future tokens in the text as it reads during training). However, CoCa departs from standard decoder transformers by skipping any cross-attention to the earlier, unimodal part of its decoder. The multimodal layers work by applying causally-masked self-attention together with the cross-attention to the output of the image encoder.
Having both unimodal and multimodal text representations throughout the course of the computations allows for the application of both contrastive and generative objectives; namely, the loss function for CoCa is a convex combination of the contrastive and captioning loss functions.
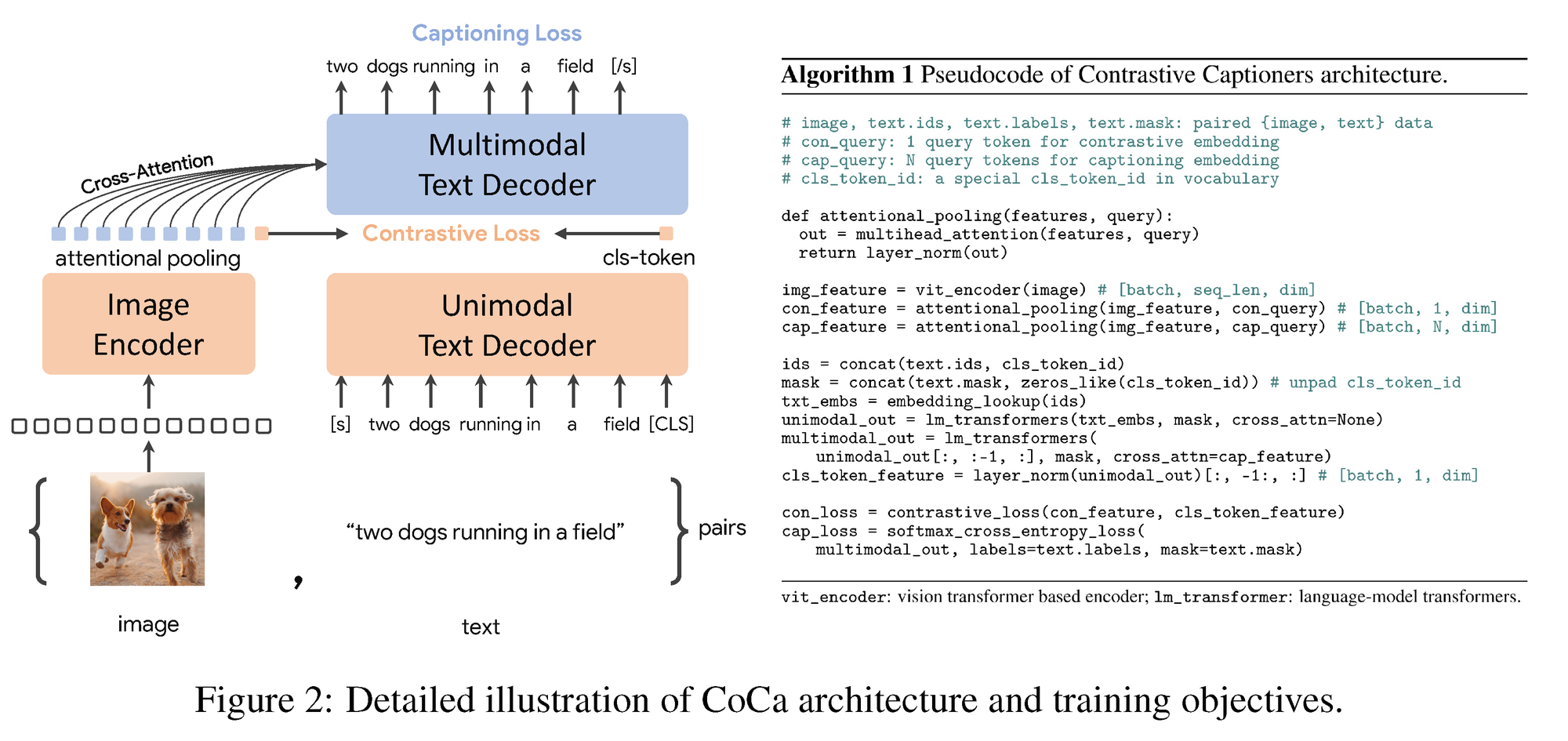
In terms of computing complexity, most of the the complexity lies in computing the two loss functions for each input pair, and the causal masking means the decoder only needs to perform a single forward propagation. Moreover, the training is able to occur with various data sources with annotated images and noisy alt-text images "by treating all labels as texts for both contrastive and generative objectives."
Downstream Tasks
The paper identifies applications to Zero-shot Transfer, Frozen-feature Evaluation, and Video Action Recognition. In particular, the model performed well when the image encoder was fixed in the pretrained model, where only a new pooler is trained to aggregate features for a downstream task.
CoCa can notably be applied for video action recognition, i.e., identifying actions taking place in a video. This happens by taking a collection of interspersed frames throughout the video and using a fixed image encoder to encode each one individually. In the context of frozen-feature, the additional pooler is trained using all of the encoded frames, specifically applying softmax cross-entropy as the loss function.
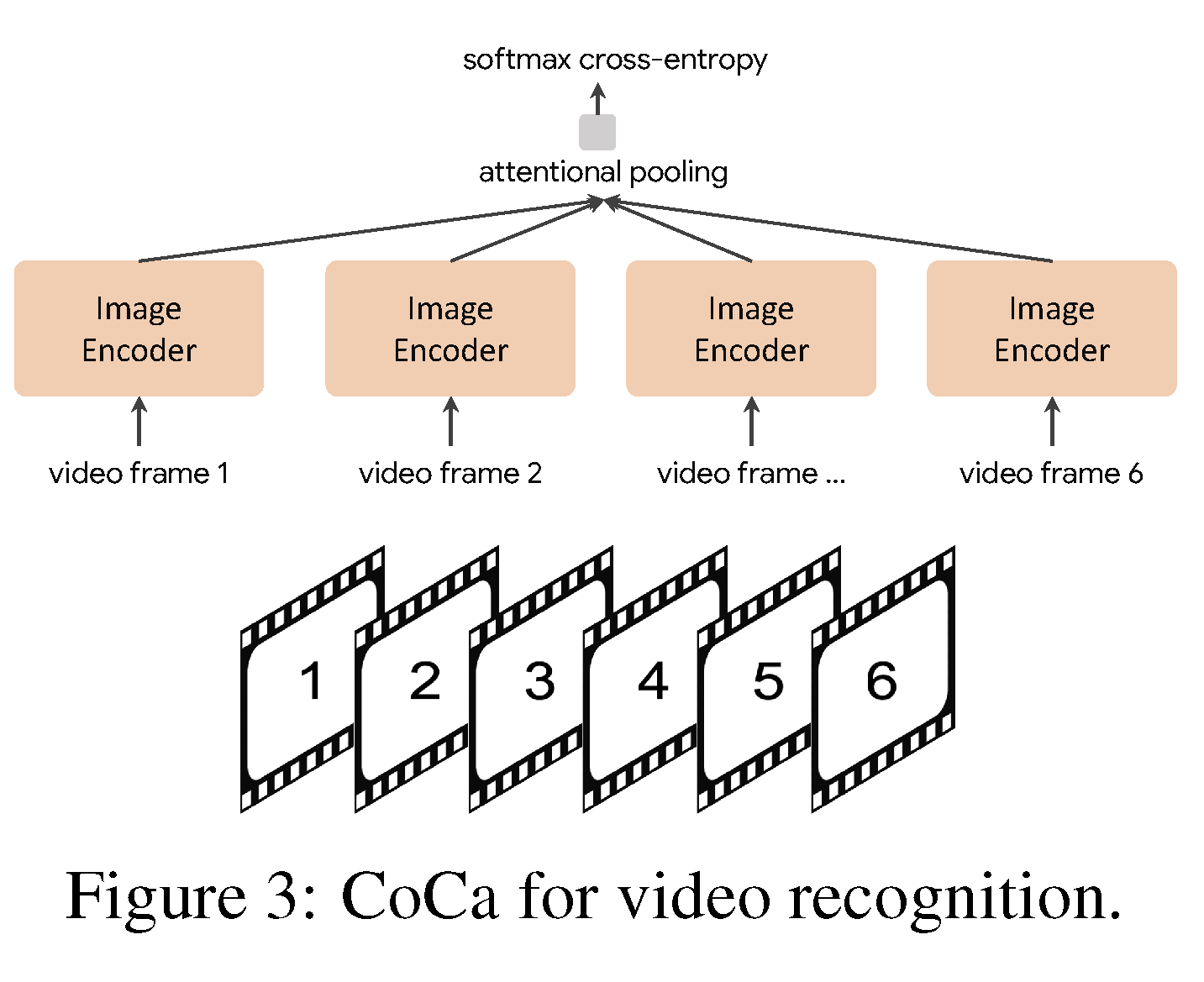
Results

CoCa outperformed other specialized pretrained models using zero-shot transfer or minimal task-specific adaptation. CoCa scored 86.3% zero-shot accuracy on classifying ImageNet. Slight fine-tuning improved its performance on ImageNet to 91.0%.
The Main Results featured in the preprint explain how CoCa performed in Visual Recognition Tasks like Frozen-Feature and Finetuning; Crossmodal Alignment Tasks like Zero-Shot Image-Text Retrieval, Zero-Shot Image Classification, and Zero-Shot Video Retrieval; Image Captioning and Multimodal Understanding Tasks like Multimodal Understanding, and Image Caption. There are additional justifications for why to separate the decoder in half in terms of number of layers dedicated to each modal decoder, and other hyper-parameter choices.
The figure below compares CoCa with other image-text foundation models without task-specific customizations and multiple state-of-the-art task-specialized models.
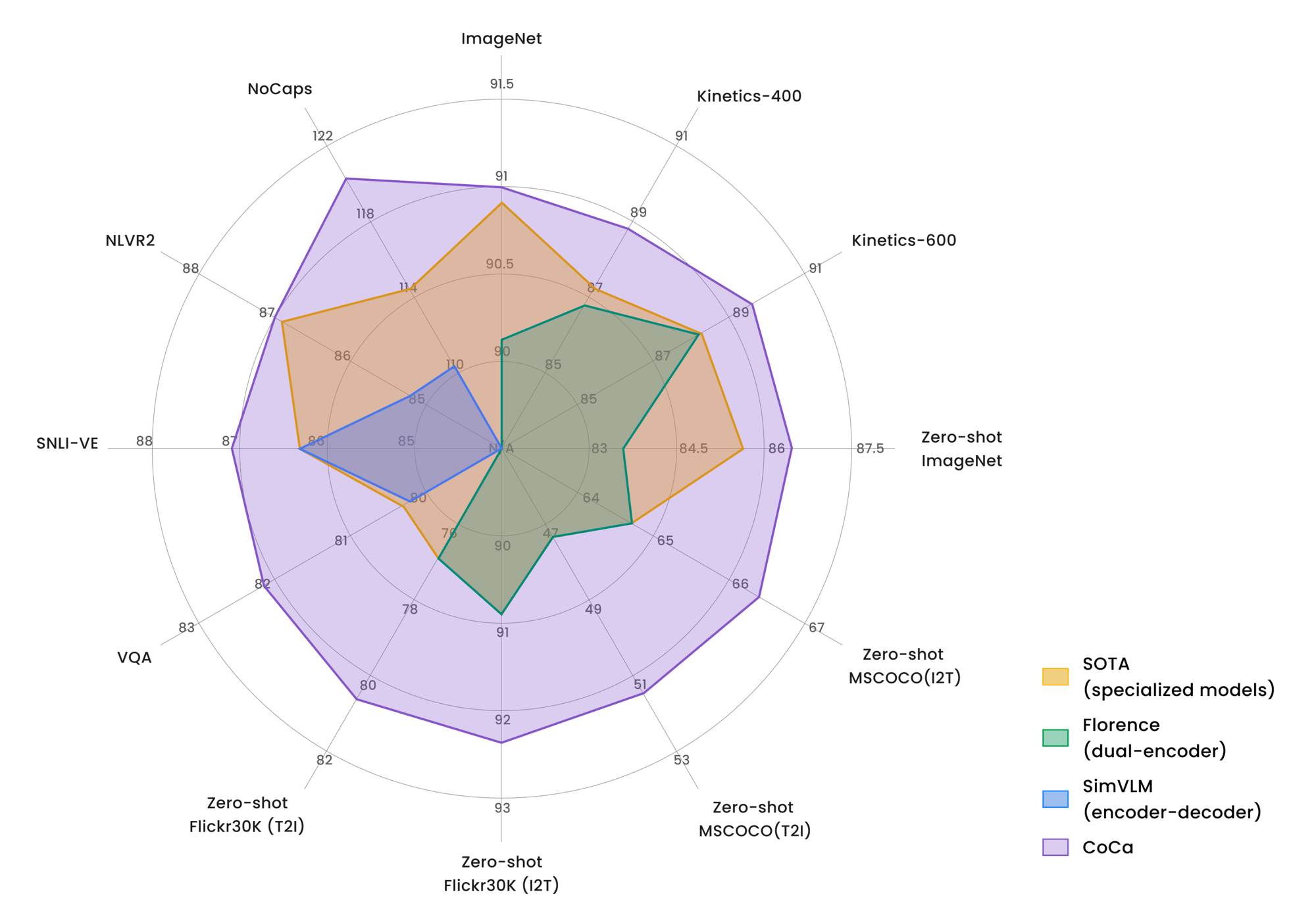
CoCa was shown to have the capacity to transfer to a wide range of downstream tasks. Its capabilities were also noted to be more robust int he event it encounters corrupted images.
Glossary of Basic Terms for Reference
- Encoder: The encoder is the first component of the model that processes the input data and creates a fixed-length representation (embedding) of the input sequence. Can be described as a stack of RNN layers.
- Decoder: The decoder is the second component of the model that takes the fixed-length representation (context vector) generated by the encoder and uses it to produce the desired output sequence.
- Modality: a format or representation type of data; i.e., text, image, video, audio, etc.
- Context Vector: the fixed-length representation produced by an encoder, representing the features/semantics of its respective modality.
- Unimodal Decoder Layer: a step in the model that decodes a context vector in a particular modality and generates an output.
- Fusion Layer: combines information from multiple modalities.
- Attention: introduced to solve the vanishing gradient problem where RNN layers do not remember many tokens into the past in a sequence.
Further Resources
Find a PyTorch CoCa implementation here.
I found great guides on Attention, Transformers, and Multihead Self Attention through AI Summer while reading through this paper.